Life in the FastLanes
Decoding > 100 billion integers per second with scalar Rust.Tue Jun 18 2024
Originally posted: https://blog.spiraldb.com/life-in-the-fastlanes/
Vortex is our open-source Rust library for compressed Arrow. If you want to have compressed Arrow arrays on-disk, in-memory, or over-the-wire, Vortex is designed to help out.
Of course, a compressed Arrow library wouldn’t be much good without a set of compression codecs. While Vortex codecs are fully extensible, we ship a handful of state-of-the-art codecs out of the box, including the namesake of this post: FastLanes.
Be sure to check out and star our Rust port of FastLanes 🦀 on GitHub.
FastLanes
The FastLanes paper was published in May 2023 by Azim Afroozeh and Peter Boncz from the CWI in Amsterdam.
Breaking down the title of the paper, we have two statements:
- Decoding >100 billion integers per second…
- …with scalar code
To put the first statement into context, on a regular MacBook CPU running at ~3.5GHz, that would equate to ~28.5 integers per CPU cycle. This is of course just napkin math, not a benchmarking result, so take it with a hefty pinch of salt. But for those even somewhat familiar with how a CPU works, that’s a really quite astounding number.
The second point is perhaps more interesting. Scalar code, in this case, means there is no use of any architecture-specific compiler intrinsics as would typically be required to make effective use of SIMD (single instruction, multiple data) instructions.
FastLanes therefore provides a way to write incredibly high-performance compression codecs in a fully portable way.
There’s no messing around with intrinsics, and no use of SIMD abstractions like Rust’s std::simd or C++’s Highway. Instead relying entirely on LLVM’s ability to auto-vectorize certain loops.
Our exploration of FastLanes will be split into two parts:
- This first post looks at the main building block of FastLanes: auto-vectorized bit-packing.
- The second post will then look at the FastLanes unified transpose ordering. A clever shuffling of array elements that enables SIMD parallelism for encodings that appear to be very serial, such as delta and run-length.
Let’s start with a general refresher on bit-packing.
Bit-packing
In the fast-paced, high-stakes world of compression, the real game is all about unsigned integers. If we can convert our data into low-valued positive integers, we’re doing pretty well. That’s because bit-packing is incredibly simple and incredibly effective.
👀 We’ll see just how important this idea is in a future post on compressing floating point data with ALP.
Suppose we have a small unsigned 32-bit integer, say, 17. The (big-endian) bits in memory look like this:
00000000 00000000 00000000 00010001It is immediately obvious in binary form that there’s a lot of unused bits. We only really care about the final 5-bits worth of information.
So when we talk about bit-packing u32 into u5, we mean taking a sequence of 32-bit integers and squeezing them into adjacent runs of 5 bits.
If we ever find ourselves with signed negative signed integers, we can easily get rid of the sign bit by applying either frame-of-reference encoding (adding an offset to shift all numbers positive), or zig-zag encoding (rotating all the bits left by one so the sign bit moves to the last position).
LLVM Loop Vectorizer
Not all loops can be auto-vectorized to use SIMD. Instead of asking the general and very complex question of which ones can be, we’re going to look at the single case of loop vectorization that’s relevant to FastLanes.
In this case, vectorization occurs when each iteration of the loop applies the same set of instructions to the same relative offsets of the input and output arrays.
The following example shows each iteration of the loop executing two loads, an addition, and a store operation.
for i in 0..N {
a[i] = b[i] + c[i];
}Supposing our CPU supports these three operations over 4-lane u32 SIMD registers (u32x4), then we can unroll our loop 4 times. Note that the compiler may have to add an instance of the un-vectorized loop to handle the tail when N isn’t known to be a multiple of 4).
for i in (0..N/4).step_by(4) {
a[i + 0] = b[i + 0] + c[i + 0];
a[i + 1] = b[i + 1] + c[i + 1];
a[i + 2] = b[i + 2] + c[i + 2];
a[i + 3] = b[i + 3] + c[i + 3];
}We can then see how LLVM is able to vectorize this loop to operate over 4 elements concurrently.
for i in (0..N/4).step_by(4) {
a[i..i + 4] = b[i..i + 4] + c[i..i + 4];
}If our CPU instead only supported u32x2 SIMD registers, the loop vectorizer would unroll it only twice.
The tricky thing with bit-packing, and the problem that FastLanes addresses, is how to layout the packed bits such that the same compressed array data can be read on both of these CPUs, whether they are running with 2 lanes, 4 lanes, or even up to 32 lanes.
FastLanes Bit-packing
FastLanes implements all of its codecs over individual vectors of 1024 elements.
We're going to walk through the FastLanes scalar implementation of bit-packing u8 into u3 in semi-pseudo Rust. We therefore define our unpacked width T = 8, and our packed width W = 3.
Note that for the sake of simplicity and alignment, our packed array also has type u8 even though it contains contiguous 3-bit integers. The output array will therefore have length W * 1024 / T = 384.
This gives us our function signature.
fn pack_u8_u3(elems: &[u8; 1024], packed: &mut [u8; 384]) {
...
}MM1024
The FastLanes paper defines a virtual 1024-bit SIMD register called MM1024. “MM” is a nod to the naming convention of Intel SIMD registers, and we say “virtual” because the widest SIMD register today has only 512 bits.
Conceptually, FastLanes uses these MM1024 registers to process batches of 1024 elements, 1024 bits at a time.
If we write our code to support these 1024-bit registers, then it necessarily supports all smaller SIMD widths too. The compiler can simply swap a single MM1024 add instruction for 2x512-bit instructions, 4x256-bit instructions, and so on.
Do you even vectorize?
Armed with our newfound knowledge of loop vectorization and a magic 1024-bit SIMD register, we can write ourselves an outer-loop such that–were we to compile for our uber-modern magic CPU–it would vectorize to use MM1024 registers. Sadly, such a CPU doesn’t yet exist.
This means we want an outer-loop of 1024-bits / T = 128 virtual SIMD lanes.
fn pack_u8_u3(input: &[u8; 1024], packed: &mut [u8; 384]) {
for lane in 0..128 {
...
}
}For example, if our CPU only supports 256-bit SIMD, then LLVM will vectorize our loop to run over the maximum possible 256-bits / T = 32 lanes at a time.
Element iteration order
With our loop iterating over 1024-bits / T = 128 lanes, it’s helpful to visualize what this means for our input array. We first imagine rearranging our vector into T rows of 128 lanes (columns) each.
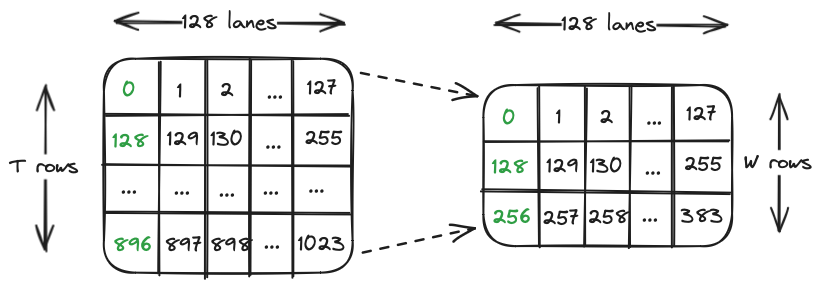
Within each lane, we step forward 128 elements at a time over T rows in order to pack T * T bits into T * W bits. Our output array can be laid out analogously, and is also accessed in increments of 128.
Looking shifty…
Each input element must then be masked and shifted into the correct position in the output array. The first integer packs into bits 0-3, and the second into 3-6. The third is where things get fiddly, we need to store 2 bit in the remainder of the first output byte, and carry 1 bit over the next output byte.
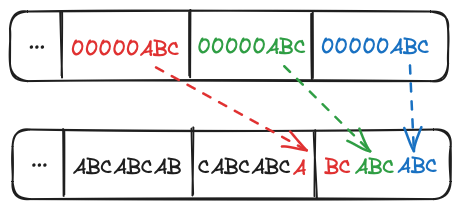
Here's one I made earlier
We can now write a body for our outer loop that takes each element of the input lane, applies a 3-bit mask, shifts the masked bits into position, accumulates them into a tmp variable, and then writes to one of W packed output elements.
fn pack_u8_u3(input: &[u8; 1024], packed: &mut [u8; 384]) {
const MASK: u8 = 0b00000111;
let mut src: u8;
let mut tmp: u8;
for lane in 0..128 {
src = input[128 * 0 + lane] & MASK;
tmp = src;
src = input[128 * 1 + lane] & MASK;
tmp |= src << 3;
src = input[128 * 2 + lane] & MASK;
tmp |= src << 6;
packed[128 * 0 + lane] = tmp;
tmp = src >> 2;
// Last bit from the previous input src = input[128 * 3 + lane] & MASK;
tmp |= src << 1;
src = input[128 * 4 + lane] & MASK;
tmp |= src << 4;
src = input[128 * 5 + lane] & MASK;
tmp |= src << 7;
packed[128 * 1 + lane] = tmp;
tmp = src >> 1;
// Two bits from the previous input src = input[128 * 6 + lane] & MASK;
tmp |= src << 2;
src = input[128 * 7 + lane] & MASK;
tmp |= src << 5;
packed[128 * 2 + lane] = tmp;
}
}Full Rust implementation of the u8 -> u3 bit-packing kernel
Into the weeds
All that’s left is to verify that the code does indeed compile to what we expect using the cargo-show-asm tool.
bitpacking::pack_u8_u3:
Lfunc_begin303:
.cfi_startproc
movi.16b v0, #7
ldp q1, q7, [x0]
and.16b v3, v1, v0
ldp q1, q16, [x0, #128]
shl.16b v4, v1, #3
movi.16b v1, #3
movi.16b v2, #56
and.16b v4, v4, v2
...Extract of the generated ASM with ARM NEON
On an M2 MacBook, the ARM suffix “.16b” indicates that we’re operating with a u8x16 SIMD register, as we’d expect with ARM’s 128-bit NEON instruction set.
FastLanes Rust
Partly as an exercise to better understand FastLanes, and partly to avoid using FFI, we wrote a Rust port of FastLanes 🦀.
While the original FastLanes consists of several thousand lines of generated code, the Rust implementation makes extensive use of macros to compute the mask and shift of each element at compile-time.
The FastLanes Rust implementation of the above kernel, admittedly with most of the logic hidden inside the pack! macro, looks like this:
fn pack_u8_u3(input: &[u8; 1024], packed: &mut [u8; 384]) {
for lane in 0..128 {
pack!(u8, 3, packed, lane, |$idx| { input[$idx] });
}
}The bit-packing kernel from FastLanes Rust
This structure makes it trivial to implement additional compression codecs, like frame-of-reference and delta.
Coming in Part II
- ↔️ We explore how the FastLanes unified transpose order enables vectorization of delta encoding.
- 🏎️ We learn how to implement our own FastLanes-accelerated compression codecs.
- 🌶️ We look at why FastLanes Rust is NOT binary compatible with the original FastLanes